我们都知道大模型都是由各种算法组成的,那怎么看似简单的代码,如何变成让人惊艳的“智能大脑”的?这篇文章,我们来分析下算法、结构的路程和进步。

你有没有想过,AI 是如何从一个个看似简单的算法,变成了如今无所不能的“智能大脑”?
算法研究员和工程师不断设计新的 AI 算法和 AI 模型提升预测效果,其预测效果不断取得突破性进展。
但是新的算法和模型结构,需要 AI 开发框架提供便于对 AI 范式的编程表达力和灵活性,对执行性能优化有可能会改变原有假设,进而产生了对 AI 系统对于 AI 开发框架的开发过程和 AI 编译器的执行过程优化提出了新的挑战,因而促进了 AI 系统的发展。
一、精度超越传统机器学习以 MNIST 手写数字识别任务为例,其作为一个手写数字图像数据集,在早期通常用于训练和研究图像分类任务,由于其样本与数据规模较小,当前也常常用于教学。
从图中可以观察了解到不同的机器学习算法取得的效果以及趋势:1998 年,简单的 CNN 可以接近 SVM 最好效果。
2012 年,CNN 可以将错误率降低到 0.23% (2012),这样的结果已经可以和人所达到的错误率 0.2% 非常接近。
神经网络模型在 MNIST 数据集上相比传统机器学习模型的表现,让研究者们看到了神经网络模型提升预测效果的潜力,进而不断尝试新的神经网络模型和在更复杂的数据集上进行验证。
神经网络算法在准确度和错误率上的效果提升,让不同应用场景上的问题,取得突破进展或让领域研发人员看到相应潜力,是驱动不同行业不断投入研发 AI 算法的动力。
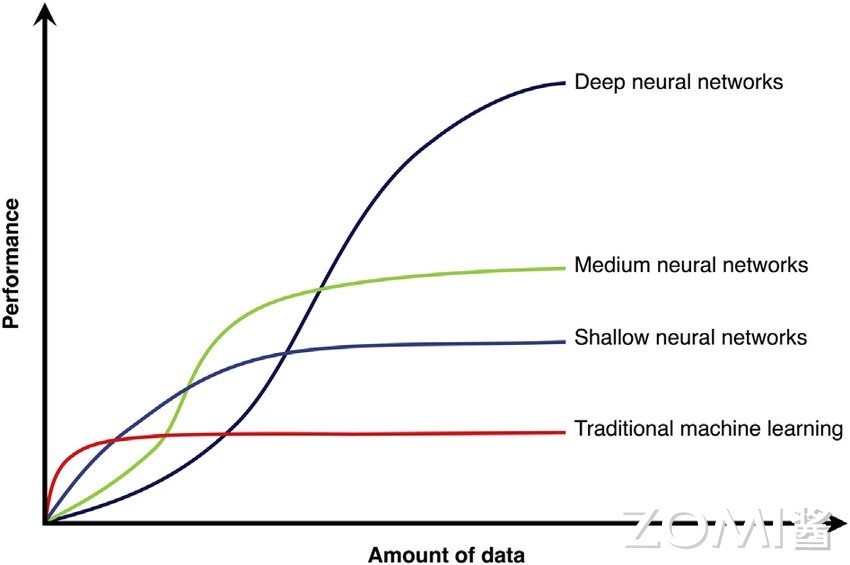 二、公开数据集上突破
二、公开数据集上突破随着每年 ImageNet 数据集上的新模型取得突破,新的神经网络模型结构和训练方式的潜力。更深、更大的模型结构有潜力提升当前预测的效果。
1998 年的 Lenet 到 2012 年的 AlexNet,不仅效果提升,模型变大,同时引入了 GPU 训练,新的计算层(如 ReLU 等)。
到 2015 年的 Inception,模型的计算图进一步复杂,且有新的计算层被提出。
2015 年 ResNet 模型层数进一步加深,甚至达到上百层。
到 2019 年 MobileNet3 的 NAS,模型设计逐渐朝着自动化的方式进行设计,错误率进一步降低到 6.7% 以下。
新的模型不断在以下方面演化进而提升效果:1)更好的激活函数和层,如 ReLU、Batch Norm 等;2)更深更大的网络结构和更多的模型权重;3)更好的训练技巧: 正则化(Regularization)、初始化(Initialization)、学习方法(Learning Methods),自动化机器学习与模型结构搜索等。
上述取得更好效果的技巧和设计,驱动算法工程师与研究员不断投入,同时也要求 AI 系统提供新的算子(Operator)支持与优化,进而驱动 AI 开发框架和 AI 编译器对前端、中间表达和系统算法协同设计的演进和发展。
三、算力与体系结构进步从 1960 年以来,计算机性能的增长主要来自摩尔定律,到二十世纪初大概增长了 108 倍。但是由于摩尔定律的停滞,性能的增长逐渐放缓了。单纯靠工艺尺寸的进步,无法满足各种应用对性能的要求。
于是,人们就开始为应用定制专用芯片,通过消除通用处理器中冗余的功能部分,来进一步提高对特定应用的计算性能。如图形图像处理器 GPU 就对图像类算法进行专用硬件加速。如图所示后来出现 GPGPU,即通用 GPU,对适合于抽象为单指令流多数据流(SIMD)或者单指令多线程(SIMT)的并行算法与工作应用负载都能起到惊人的加速效果。
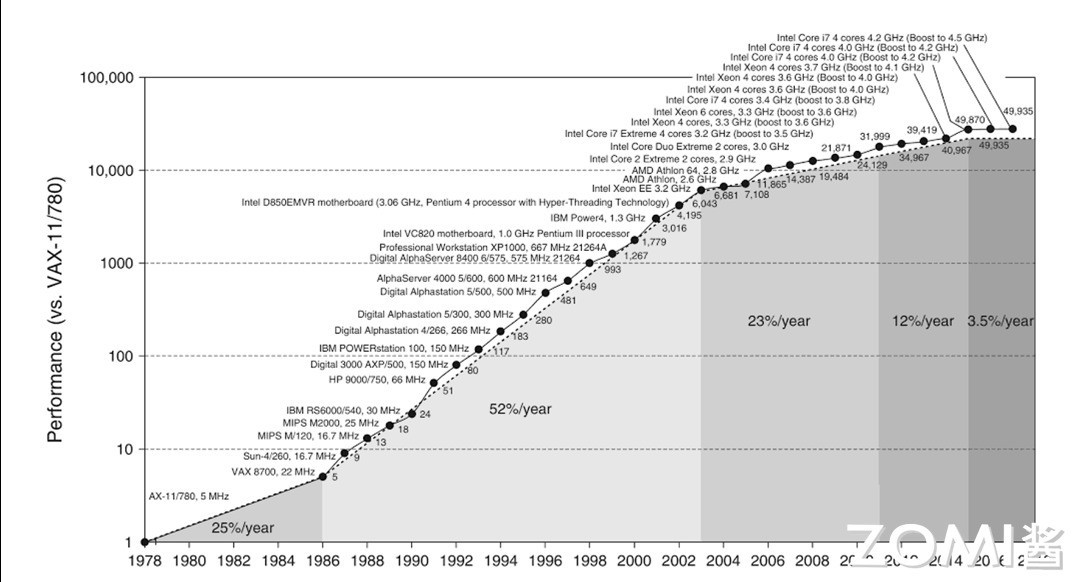
为了更高的性能,近年来 AI 芯片也大放光彩。
其中一个代表就是谷歌 TPU(Tensor Processing Unit),通过对深度学习模型中的算子进行抽象,转换为矩阵乘法或非线性变换,根据专用负载特点进一步定制流水线化执行的脉动阵列(Systolic Array),进一步减少访存提升计算密度,提高了 AI 模型的执行性能。
华为昇腾 NPU(神经网络处理器)针对矩阵运算专门优化设计,可解决传统芯片在神经网络运算时效率低下的问题。
此外,华为达芬奇架构面向 AI 计算设计,通过独创 3D Cube 设计,每时钟周期可进行 4096 次 MAC 运算,为 AI 提供强大算力支持。
除了算子层面驱动的定制,AI 层面的计算负载本身在算法层常常应用的稀疏性和量化等加速手段也逐渐被硬件厂商,根据通用算子定制到专用加速器中,在专用计算领域进一步协同优化加速。通过定制化硬件,厂商又将处理器性能提升了大约 105 量级。
然而可惜的是,经过这么多年的发展,虽然处理器性能提升这么多,我们机器的数值运算能力早已是人类望尘莫及了,AI 芯片内部执行的程序代码仍然是人类指定的固定代码,智能程度还远远不及生物大脑。从智力程度来说,大约也就只相当于啮齿动物,距离人类还有一定距离。
可以看到随着硬件的发展,虽然算力逐渐逼近人脑,让 AI 取得了突破。
但是我们也看到,算力还是可能在短期内成为瓶颈,那么 AI 系统的性能下一代的出路在哪?
我们在后面会看到,除了单独芯片的不断迭代进行性能放大(Scale Up),系统工程师不断设计更好的分布式计算系统将计算并行,来达到向外扩展(Scale Out),同时发掘深度学习的作业特点,如稀疏性等通过算法,系统硬件协同设计,进一步提升计算效率和性能。
本文由 @章鱼AI小丸子 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务